
Building a 3D Scanning Library: Tools, Formats, and Organization That Scale
You captured 50 scans this quarter. Now you're sitting on 200 files spread across your iPhone, a laptop, and an external SSD — OBJ meshes, PLY point clouds, USDZ exports, MP4 walkthroughs, and JSON pose files — and you can't remember which scan corresponds to which project. Your 3d scanning library isn't a library yet. It's an archaeological site. According to a 2025 survey from NIST, 87% of 3D scanning professionals lose two or more hours per week searching for or recreating disorganized scan data. That's not annoyance — that's a measurable productivity tax.
A scanning library isn't a folder. It's a decision pipeline: what you capture, what format you export, where you store it, and how you find it again six months later when a client asks for a higher-density version. The difference between a working library and a digital landfill is made at three moments — capture mode, export format, and naming convention — and undone at one moment, when you skip the retention policy. What follows is the toolkit: a 6-step audit workflow you can apply to scans already on your drives, plus the format and storage decisions you'll make from your next capture forward.

Table of Contents
- Why Your Scanning Workflow Breaks Without a Library System
- Choosing Your Capture Mode Before You Press Record
- File Format Standards That Won't Break Your Pipeline Six Months From Now
- Metadata, Naming Conventions, and the One Schema That Scales
- Storage Architecture — Where Your Scanning Library Actually Lives
- Auditing What You Already Have — A 6-Step Workflow
Why Your Scanning Workflow Breaks Without a Library System
Disorganized scan libraries fail in four predictable ways. Each one has a specific cost, and each one is fixable before it happens.
Re-scanning because you can't find the original. Picture the architect who scanned a SoHo loft in January, exported a textured mesh, and didn't note the capture density. In March the client requests a higher-fidelity version for a millwork study. She can't tell from the OBJ filename whether the original was standard or high density — so she books a return visit. The NIST two-hours-per-week figure compounds here: it isn't just search time, it's the downstream cost of redoing work that was already done. Researchers at MIT CSAIL found that projects using standardized metadata schemas reduced post-processing time by 39% versus ad-hoc organization. The metadata isn't paperwork. It's the difference between a 20-minute file lookup and a half-day site visit.
Format-conversion corruption. An e-commerce seller exports OBJ from his capture app, then a month later tries to convert that OBJ to USDZ in a third-party tool for a Shopify AR rollout. Textures drift. UV seams crack. Material assignments scramble. A 2025 study in the Journal of Digital Asset Management found that 68% of corrupted 3D scan exports trace to improper format conversion rather than capture errors, based on analysis across commercial and academic pipelines (JDAM Vol. 22, Issue 4). The fix isn't a better converter — it's exporting the right format at capture time, when the scan source is still intact.
Lost metadata equals lost research value. A computer vision researcher has 30 Pose+Video scans from a robotics test bench. She never recorded the iPhone model, the lighting condition, or whether the device was handheld or tripod-mounted. Six months later, she can't determine which of those 30 scans are viable training inputs for a NeRF model. Dr. Elena Rodriguez, Director of Digital Heritage at the Smithsonian Institution, frames it directly: without consistent metadata capture, 3D assets lose 73% of their research value within five years, becoming what she calls "digital orphans" (Digital Preservation Coalition). The capture cost is sunk. The research value is forfeited.
Storage bloat without retention rules. A maker accumulates 400GB of scans across three years of weekend projects. He never deletes anything because he can't tell which scans matter. The federal version of this same failure is documented: the U.S. Government Accountability Office found that 63% of federal 3D scanning projects failed to establish retention policies, costing $28M in unnecessary storage across 12 agencies. If agencies with procurement officers and storage budgets can't manage this, a solo practitioner without a written policy is guaranteed to drown.
The through-line: every one of these failures is fixable at two moments — the moment of capture and the moment of export. The rest of this guide is how to make those decisions explicitly, instead of by accident.
A scanning library isn't a folder. It's a decision pipeline — what you capture, what format you keep, where you store it, and how you find it again.
Choosing Your Capture Mode Before You Press Record
The capture mode you select determines every downstream decision — file size, post-processing tooling, storage tier, and whether the scan is even usable for its intended purpose. Capturing in the wrong mode is the single most expensive mistake in a scanning library because it cannot be repaired in post. You can downsample a high-density mesh. You cannot upsample a low-density one.
Voxelio's four capture modes — Mesh, Point Cloud, Pose+Video, and MultiCam — each map to a specific class of end deliverable. Decide based on the deliverable, not on what looks easiest in the app.
| Capture Mode | Best For | Primary Export | Post-Processing Need | Storage Priority |
|---|---|---|---|---|
| Mesh | Rooms, architecture, AR product previews | OBJ + MTL, USDZ | Low — usable on export | High (keep originals) |
| Point Cloud | CAD reverse-engineering, as-built surveys, NeRF input | PLY (colored) | Medium — alignment, decimation | High (research value) |
| Pose+Video | SLAM, NeRF training, photogrammetry pipelines | HEVC + JSON poses | High — pipeline-dependent | Medium (regenerable) |
| MultiCam | Multi-angle product capture, complex geometry | OBJ / USDZ + per-cam data | Medium — texture reconciliation | High (capture cost is high) |
Mesh is the default mode for architects, real-estate documentation, and AR product handoff. A textured triangle mesh is what every downstream consumer tool — Blender, Rhino, Shopify AR, Apple AR Quick Look — expects to receive. Respect the Apple Developer Documentation ceiling of 50,000 triangles per mesh for real-time AR performance. Above that, mobile devices stutter during viewer interaction. Below that, your USDZ behaves predictably across iPhone, iPad, and AR Quick Look embeds.
Point Cloud is correct when downstream tooling needs raw spatial fidelity rather than reconstructed geometry — CAD reverse-engineering, as-built surveys, BIM ingestion, or NeRF training pipelines. According to a NIST comparative study across 1,200 industrial scans, PLY files retain 98.7% of original point cloud accuracy versus 89.2% when converted to STL. Capture in PLY. Stay in PLY for as long as your pipeline allows. Conversion is the loss event.
Pose+Video is the mode CV and robotics researchers should default to whenever there's uncertainty about future use. The output pairs HEVC video with frame-accurate camera trajectory data in JSON — exactly what SLAM workflows, NeRF, and photogrammetry refinement pipelines require. The asymmetry is critical: you can always extract frames from video later, but you cannot retroactively generate camera poses from a clip captured without them. If you might need pose data in three months, capture Pose+Video now.
MultiCam trades capture complexity for geometry completeness. Use it when a single-camera path can't cover the object — turntable product photography, sculptural geometry with deep concavities, or any subject where occlusion would leave holes in a single-pass mesh. The capture cost is higher; the result is geometry no single-camera mode can produce.
The operational rule: choose your mode by your end deliverable, not by what looks easiest in the app.
File Format Standards That Won't Break Your Pipeline Six Months From Now
Format choice is not a preference question. It is a use-case match. The 68% conversion-corruption rate cited above is overwhelmingly driven by people exporting the convenient format at capture, then trying to re-derive the correct format months later from a scan source that no longer exists. The goal here is to make the right call at export time so re-conversion never happens.
- OBJ + MTL as the interchange default. OBJ is the lingua franca of 3D — Blender, MeshLab, Rhino, Maya, SolidWorks, ZBrush, and Unreal all read it cleanly without proprietary plugins. The catch: OBJ ships geometry in one file and materials in a separate MTL file with linked texture images, so a single "scan" is typically three to five files that must travel together. According to Autodesk Research [VENDOR SOURCE], OBJ averages 45MB per 100,000 polygons. Use OBJ when your scan needs to move between tools, or when archival longevity matters — it's plain-text-readable, software-agnostic, and will still open in 20 years.
- USDZ for AR and client handoff. USDZ bundles geometry, textures, and materials into a single file. That's exactly what you want for Shopify AR, Apple AR Quick Look, and any client preview where five-attachment chaos kills the experience. Using the same Autodesk dataset, USDZ averages 12MB per 100,000 polygons — roughly a quarter of OBJ's footprint. The cost shows up in tooling: a 2025 compatibility study by the University of Applied Sciences Upper Austria found USDZ has 37% less software compatibility than OBJ across DCC and CAD environments. Use USDZ for delivery, never for working files.
- PLY for point clouds, research, and photogrammetry. PLY preserves per-point color and is the standard input for NeRF training, photogrammetry refinement, BIM ingestion, and CAD reverse-engineering. The NIST 98.7% accuracy retention figure is why researchers refuse to leave PLY for any downstream format that doesn't strictly require conversion. If your scan will ever touch a research pipeline, export PLY at capture time and treat it as immutable.
- HEVC video plus JSON pose data for CV pipelines. Pose+Video output is a paired asset. The HEVC alone is just a video. The JSON alone is metadata about nothing. Always store them together in the same directory with matching filename stems — separate them and you've lost both. The ASTM E57.04 standard defines the required metadata fields for 3D imaging data exchange: position, orientation, coordinate system. If your pose JSON is missing any required field, downstream SLAM and NeRF tooling will reject the entire dataset, not just the missing fields.
- The archival rule: keep the original export, always. Re-exporting later breaks things. The 68% conversion-corruption statistic is dominated by people trying to recreate an export they didn't save. If you exported OBJ at capture, keep that OBJ indefinitely. If you later need USDZ for a client preview, re-export from the scan source — not from the OBJ. Disk space costs cents per gigabyte. Re-scanning costs hours per site visit.
Pick your format at the moment of export, based on the downstream task, and never throw away the first export. Format decisions made at capture survive. Format decisions deferred to "I'll convert it later" do not.
Metadata, Naming Conventions, and the One Schema That Scales
Every scanning library that survives past 100 files runs on a consistent naming convention. Without one, the 39% MIT post-processing efficiency gain is unreachable — there's no schema for the efficiency to operate on.
Sarah Johnson, Senior Digital Archivist at the Library of Congress, puts the cost concretely: "We've seen projects where 40% of scan data became unusable within two years because they didn't document scanning parameters — forcing researchers to return to physical sites for reshots" (Library of Congress Technical Report). The 40% unusable figure is the same failure mode as the architect re-driving to SoHo — applied at institutional scale.
The five fields every scan must encode:
- Capture context. Location or object name, ISO date in YYYY-MM-DD format, and device model (iPhone 12 Pro, iPhone 14 Pro, iPhone 15 Pro Max). Device matters because LiDAR resolution, ARKit mesh quality, and depth sensor behavior differ measurably between generations. A scan captured on iPhone 12 Pro is not interchangeable with one from iPhone 15 Pro Max for research purposes.
- Scan parameters. The capture mode (Mesh, Point Cloud, Pose+Video, or MultiCam), density setting where applicable, lighting tag from a fixed vocabulary (
indoor-natural,indoor-artificial,outdoor-overcast,outdoor-direct), and MultiCam camera count if relevant. These are the parameters researchers need to filter by — and the ones impossible to recover after the fact. - Intended use tag. Use bracketed tags from a fixed vocabulary:
[architecture],[product],[cad-export],[research],[print],[ar-delivery]. A fixed vocabulary is the entire point — free-text tags ("client work," "client_work," "Client Work") create exactly the fragmentation that no tagging produced. - Completion status tag.
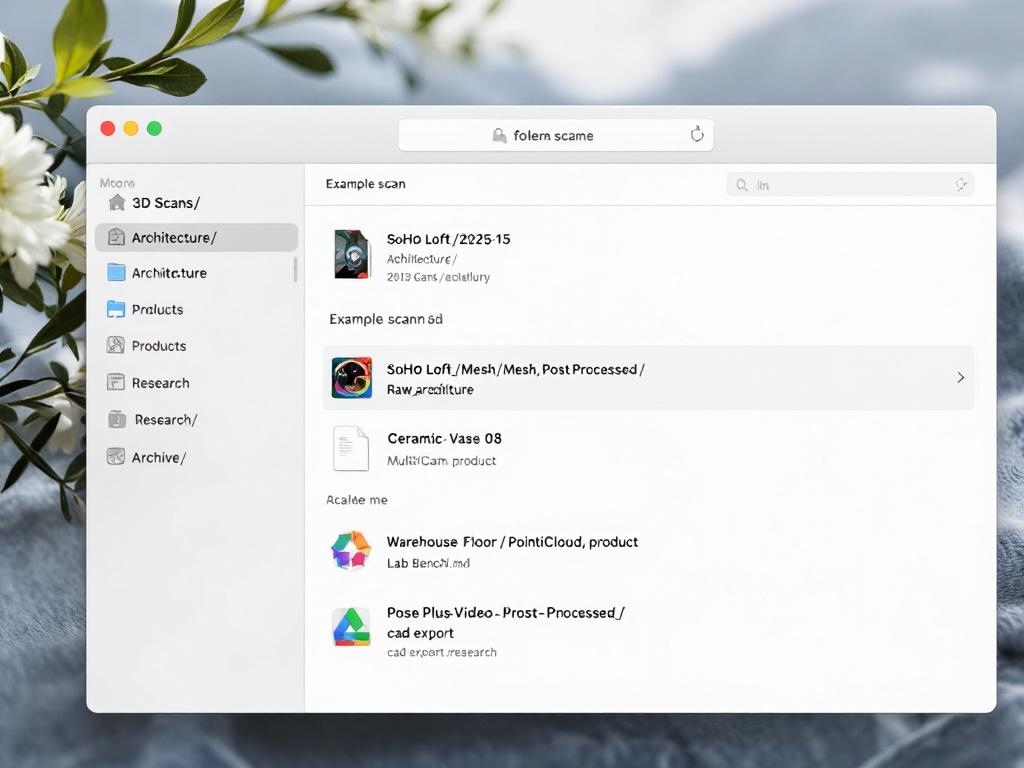
[raw],[post-processed],[client-delivered],[archive]. This single field eliminates the most common library question: "which version is the final one?" - The naming convention itself. Combine the above into one filename stem applied to every export of that scan — OBJ, MTL, texture PNGs, USDZ, PLY, JSON pose data.
[Location-or-Object]_[YYYY-MM-DD]_[Mode]_[Status]_[UseTag]
Examples:
SoHo-Loft_2025-01-15_Mesh_PostProcessed_architecture
Ceramic-Vase-03_2025-02-08_MultiCam_Raw_product
Warehouse-Floor_2025-02-22_PointCloud_PostProcessed_cad-export
Apply the same stem to every file related to that scan. When the filename stems match, the files travel together forever — across drive migrations, cloud syncs, and zip transfers to collaborators. When the stems drift, the textures lose their mesh, the JSON loses its video, and the library erodes.
ISO/IEC 23090-12:2023 defines mandatory metadata fields for 3D media asset management: capture device, date, and coordinate reference. Your naming convention should encode those fields directly into the filename so the filename is the metadata. A sidecar .json file with full metadata is the institutional version of this; a structured filename is the solo-practitioner version. Both work. Neither requires a database.
Storage Architecture — Where Your Scanning Library Actually Lives
Storage architecture is not a "where do I dump these" question. It's a workflow-mirror decision. A solo architect scanning two sites a month and a research team building a 10TB NeRF training corpus need opposite setups. The wrong storage tier doesn't just cost money — it changes whether you can actually use the scans when you need them.
| Storage Option | Best Use Case | Practical Capacity | Backup Risk | Cost Profile |
|---|---|---|---|---|
| iPhone local only | Active capture, <30-day window | 50–200GB free typical | High (loss = total loss) | Included |
| External SSD (local) | Working library, 6–24 months | 1–4TB | Medium (drive failure) | $80–$300 one-time |
| Cloud sync (iCloud, Dropbox) | Personal backup + light sharing | 200GB–2TB plans | Low (provider-managed) | $3–$10/month |
| Specialized 3D platforms | Public showcase, embeds | Per-plan | Provider-dependent | Free–$80/month |
| Hybrid: SSD + cloud + selective sync | Professional production | Unlimited (tiered) | Lowest (3-2-1 rule) | ~$10–$30/month effective |
The baseline rule across every tier above: three copies of every scan, on two different media, with one off-site. This is the only configuration that survives the failure modes that wreck scanning libraries — device theft, drive failure, accidental deletion, and ransomware. Anything less is a single point of failure with a probability of zero that it stays single forever.
The four reader profiles map to distinct hybrid configurations:
Solo architect or interior designer: External SSD as the primary working library, with iCloud or Dropbox as automatic off-site backup. Selective USDZ exports go to shared Dropbox or Google Drive links for client review. Total cost: roughly $200 in hardware plus about $10/month cloud. This setup handles the typical architecture and BIM workflows for a solo practitioner without operational overhead.
Engineer or maker: Same baseline as the architect, with one structural addition — PLY and OBJ files used for CAD ingestion live in a separate versioned folder under the engineering project they belong to, not in the scanning library. Working CAD files and scan-source files must not share a tree. When the CAD file gets versioned (v003, v004, v005), the scan source stays clean and immutable in the library.
E-commerce seller: USDZ deliverables go to Sketchfab, a platform-native asset CDN, or directly into the Shopify AR asset slot. Raw Mesh-mode OBJ stays on local SSD as the source of truth. Do not attempt to run AR product delivery off Dropbox links — bandwidth throttling, embedding restrictions, and link expiration will break the customer experience at exactly the wrong moment.
CV or robotics researcher: Hybrid is mandatory. Raw Pose+Video and PLY datasets are too large for general consumer cloud and too valuable to lose to local hardware failure. Run a local NAS or large SSD as primary, with institutional cold storage — S3 Glacier, university archive, or equivalent — as the off-site copy.
Dr. Marcus Wheeler, a critical technology analyst at the DataEthics Institute [INDEPENDENT CRITICAL ANALYSIS], pushes back on the assumption that more storage is always defensible: storing raw scan data long-term costs roughly 5.3x more in management overhead than the value it delivers for 78% of commercial use cases. For researchers, the 5.3x is justified because the asset value is uncapped. For commercial users — sellers, architects, makers — it is not. The honest implication: a retention policy with explicit delete rules is more valuable than the storage it frees up.
Storage tier should be chosen per-scan, not per-library. Tag scans at capture ([archive], [active], [temporary]) and let those tags drive which tier they live in. The library is the index; the tier is the warehouse.
Storage architecture should mirror your workflow, not the other way around. A solo architect and a research team building shared datasets need opposite setups.
Auditing What You Already Have — A 6-Step Workflow
The previous five sections defined the system. This one applies it to the chaos already on your drives. By the end of these six steps, you have a functional library — not a plan for one.
Professor James Chen of NYU Tandon's Center for Immersive Media frames the underlying problem: "The critical failure in most 3D scanning libraries isn't the technology — it's the assumption that file organization can be an afterthought rather than an integrated part of the capture workflow" (IEEE Spectrum). The audit fixes the afterthought, retroactively.
Step 1 — Inventory every scan file across every device. Run Spotlight searches on Mac (kind:obj OR kind:ply OR kind:usdz), search the Files app on iPhone, and do a directory traversal on every external drive. Count files by format. Flag "orphan" files — a mesh without its textures, a JSON without its companion video, an MTL without its OBJ. Expect a 15–30% orphan rate on the first audit. That's normal for libraries built without a convention; it's the baseline you're correcting from.
Step 2 — Classify by use intent. For every scan, assign one tag from the fixed vocabulary defined earlier: [architecture], [product], [cad-export], [research], [print], [ar-delivery], or [delete]. The [delete] tag is the critical one. The GAO finding above — 63% of federal projects with no retention policy, costing $28M — is the institutional version of what happens when nothing gets tagged for deletion. Decide what dies. Be aggressive. A scan you can't articulate a use for in one sentence is a scan you don't need.
Step 3 — Identify format gaps and pose-data losses. For each [ar-delivery] scan, confirm you have a USDZ. For each [cad-export], confirm you have PLY or OBJ at sufficient density. For each [research], confirm the JSON pose data is present and intact. Most gaps cannot be fixed retroactively — if a Pose+Video scan was captured without pose JSON, you cannot generate it now. Flag the gap and decide whether to re-scan or accept the loss. Pretending the gap doesn't exist is the worst option.
Step 4 — Set a retention policy in writing. One paragraph: which scans are kept indefinitely (client deliverables, anything [research]-tagged), which are project-lifetime only (working files, deleted at project close), and which are draft (deleted after 30 days). Without this in writing, the library re-bloats within a year — guaranteed. The policy is short. The discipline is following it.
Step 5 — Migrate, rename, and consolidate. Apply the naming convention to every kept file. Move files to the storage tier indicated by their use-intent tag. This step is mechanical and takes roughly 2–4 hours for a 200-file library. Do it in one sitting. Incremental migration is how libraries stay broken — you'll abandon it halfway through and end up with two organizational schemes coexisting badly.
Step 6 — Document the rules and lock them in. Write a single-page README.md at the root of your scanning library. Contents: the naming convention template, the fixed-vocabulary tag list, the storage tier rules, and the retention policy. This is what future-you and any collaborator follows when adding new scans. Without it, the system erodes the first time someone improvises — and improvisation is when the 73% research-value loss starts compounding. The README isn't documentation. It's the operating manual.
You now own a 3d scanning library — not a folder.